Introduction
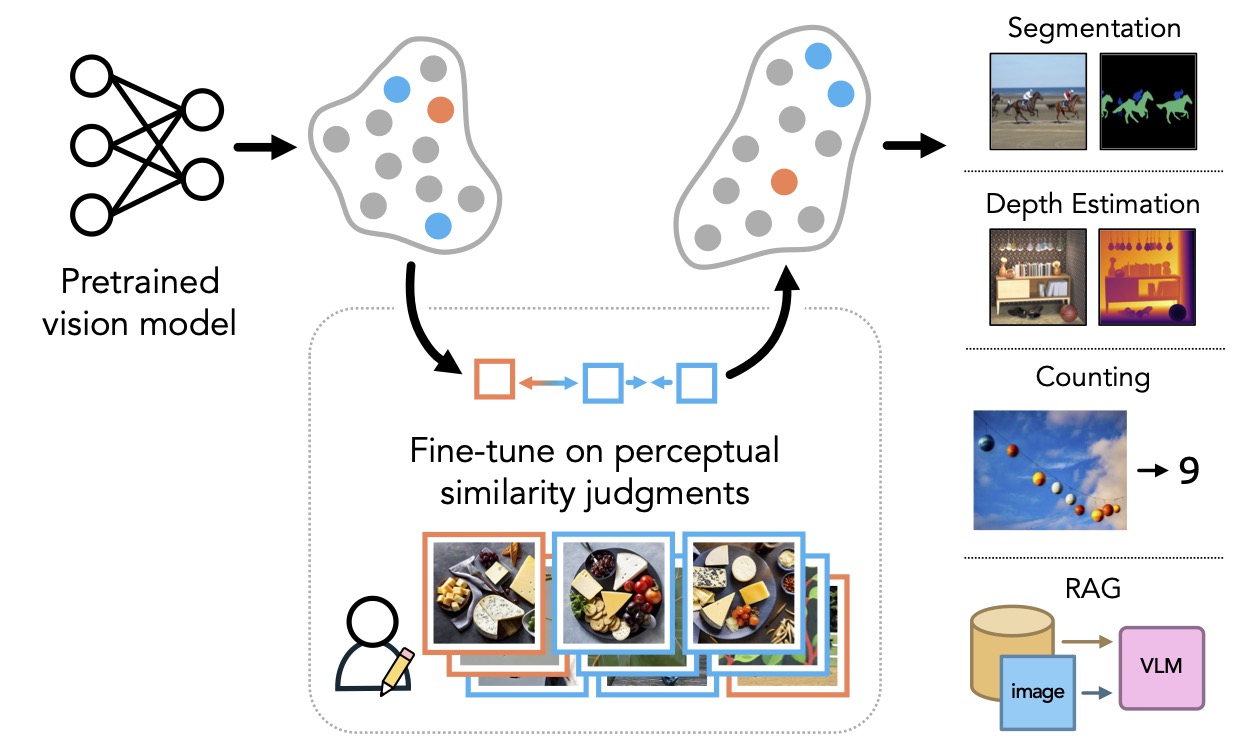
What does it mean for machines to see the world as humans do?
Our sense of similarity is crucial to how we perceive and navigate the world. Think about the rich set of factors that you notice when judging similarity: layout, color, perspective, semantics, and more. We reason about concepts and scenes, and group them together, largely based on how similar we perceive these visual characteristics to be.
While vision models have become impressively capable, they still often don't align to human judgements of visual similarity. In the language domain, we have already seen the power of aligning LLMs to human feedback; models fine-tuned with RLHF are easier for humans to interact with, predict, and interpret. But what are the effects of alignment in vision?
In this paper, we ask: Are models that "see" like humans better at just specific tasks -- such as predicting image similarity -- or are they actually better general-purpose representations?
What is the purpose of perceptual alignment?
One way to understand representations is as similarity structures: embeddings are meaningful precisely because of their similarity to other embeddings in the high-dimensional feature space. Likewise, an understanding of the visual similarities between images and concepts is critical to human perception. Perceptual alignment imposes the constraint that images should be close to each other if humans judge them to be visually similar. In doing so, it aligns the representation's similarity structure to that of human perception.
How do we align vision models?
At a high level, we align vision models to human perception by fine-tuning them on human perceptual similarity judgements from the NIGHTS dataset. NIGHTS contains 20k synthetic image triplets annotated with two alternative forced-choice judgements. Compared to other datasets (see below) the triplets in NIGHTS contain a rich set of mid-level variations, such as color, style, pose, and object count.

More precisely: We formalize this dataset as \(\mathcal{D}=\{(x, \tilde{x_0}, \tilde{x_1}), y\}\) where \(x\) is a reference image, and \(\tilde{x_0}\) and \(\tilde{x_1}\) are two variation images. The judgement \(y \in \{0,1\}\) indicates which of \(\tilde{x_0}\) and \(\tilde{x_1}\) is more similar to \(x\).
Given a pre-trained backbone \(f_{\theta}\), we measure the distance between two images \((x,\tilde{x_0})\) using the cosine distance between their respective image features \((f_{\theta}(x),f_{\theta}(\tilde{x_0}))\). We fine-tune on \(\mathcal{D}\) using a simple triplet loss that encourages a low (high) cosine distance between the more similar (dissimilar) pairs.
Using this procedure, we fine-tune both the global and patch-level features of \(f_{\theta}\) (see our paper for more details). We can think about this as a "second pre-training stage". The next step is to see if the fine-tuned representations transfer better to standard downstream tasks.
What are the benefits of perceptual alignment?
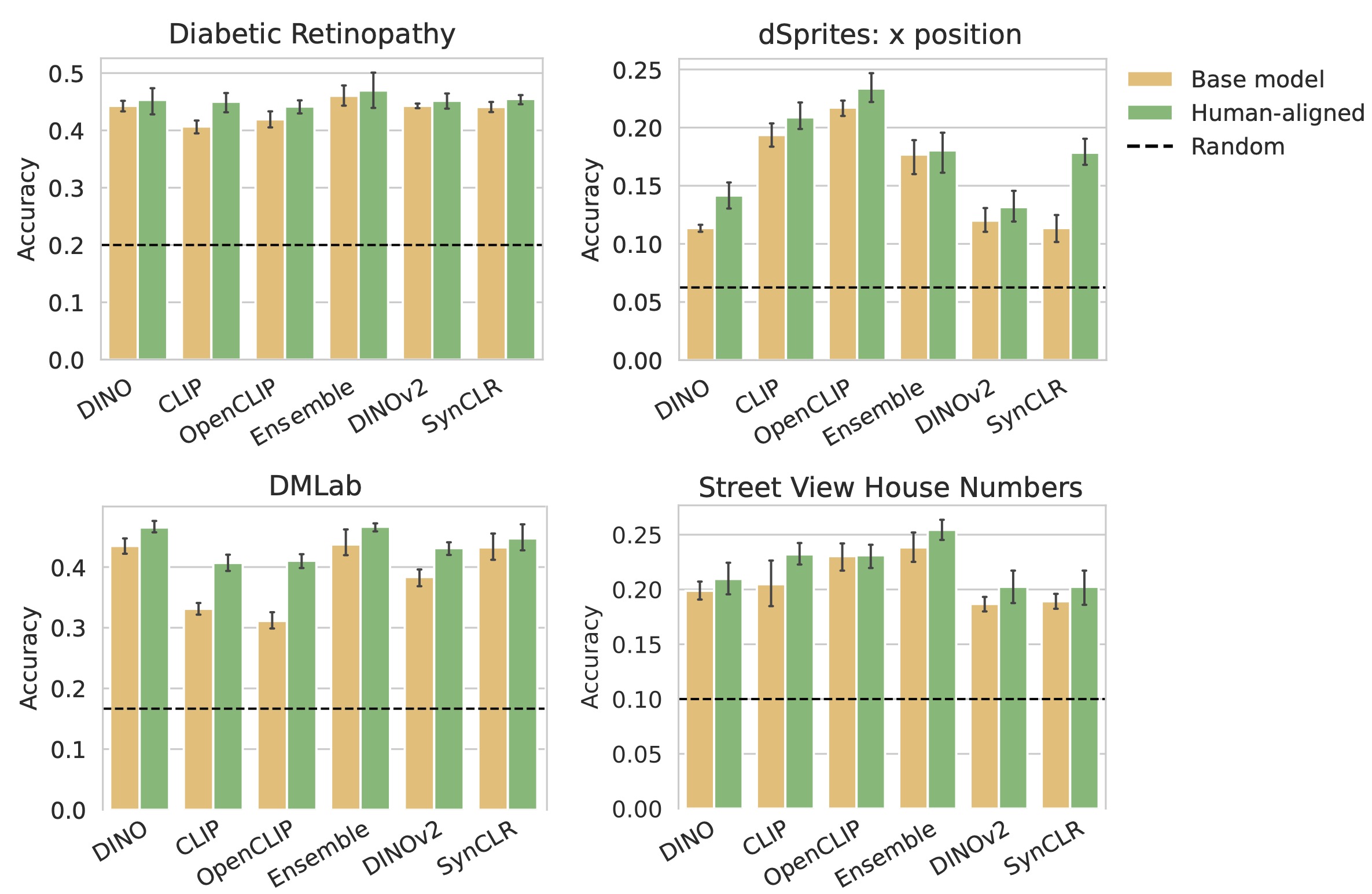
How do human-aligned models perform against non-aligned, pretrained models as general-purpose representations? We answer this by evaluating transfer performance on several global-understanding and dense prediction benchmarks.
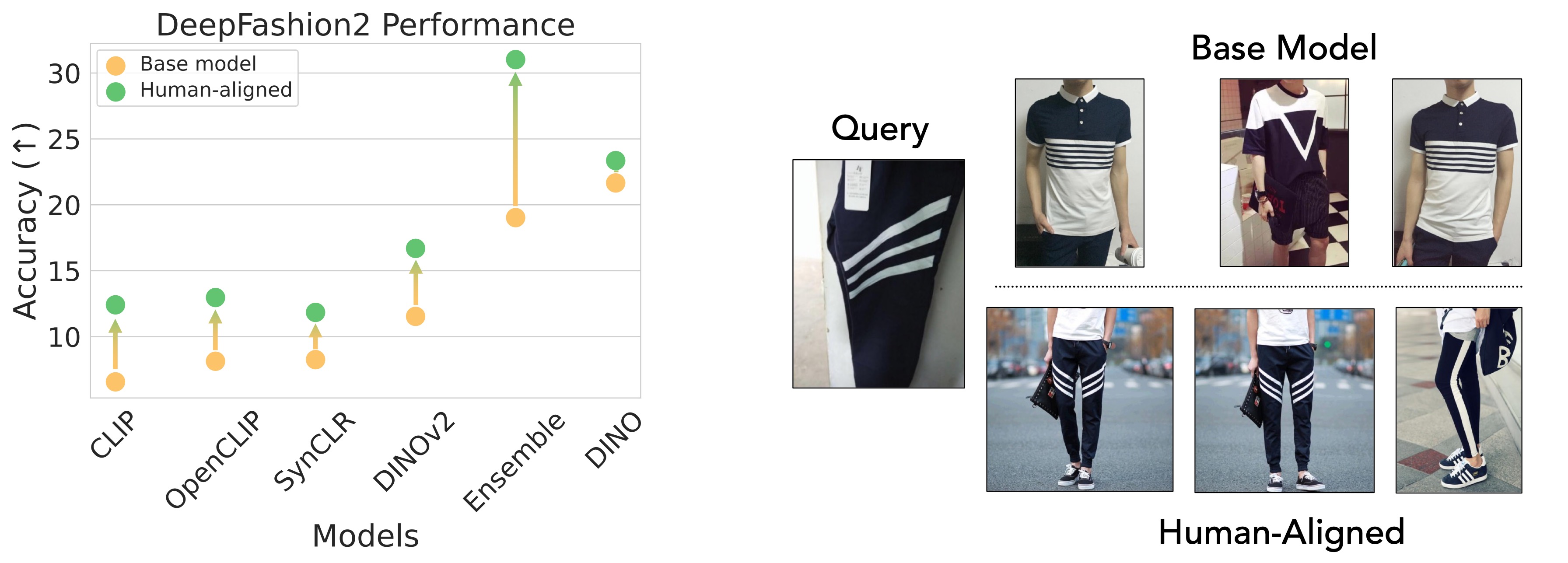
Given that we fine-tuned on image similarity judgements, one area where we might expect to see improvements is retrieval tasks. Indeed, human-aligned backbones outperform their pre-trained counterparts on instance-retrieval with the DeepFashion2 dataset.
Interestingly, these retrieval capabilities are also useful for boosting the few-shot performance of multi-modal VLMs. We test this by using OpenFlamingo to classify query images. The vision backbone is used to retrieve informative examples from the training set, which are prepended with their class labels to the query (this is also known as retrieval-augmented generation, or RAG).
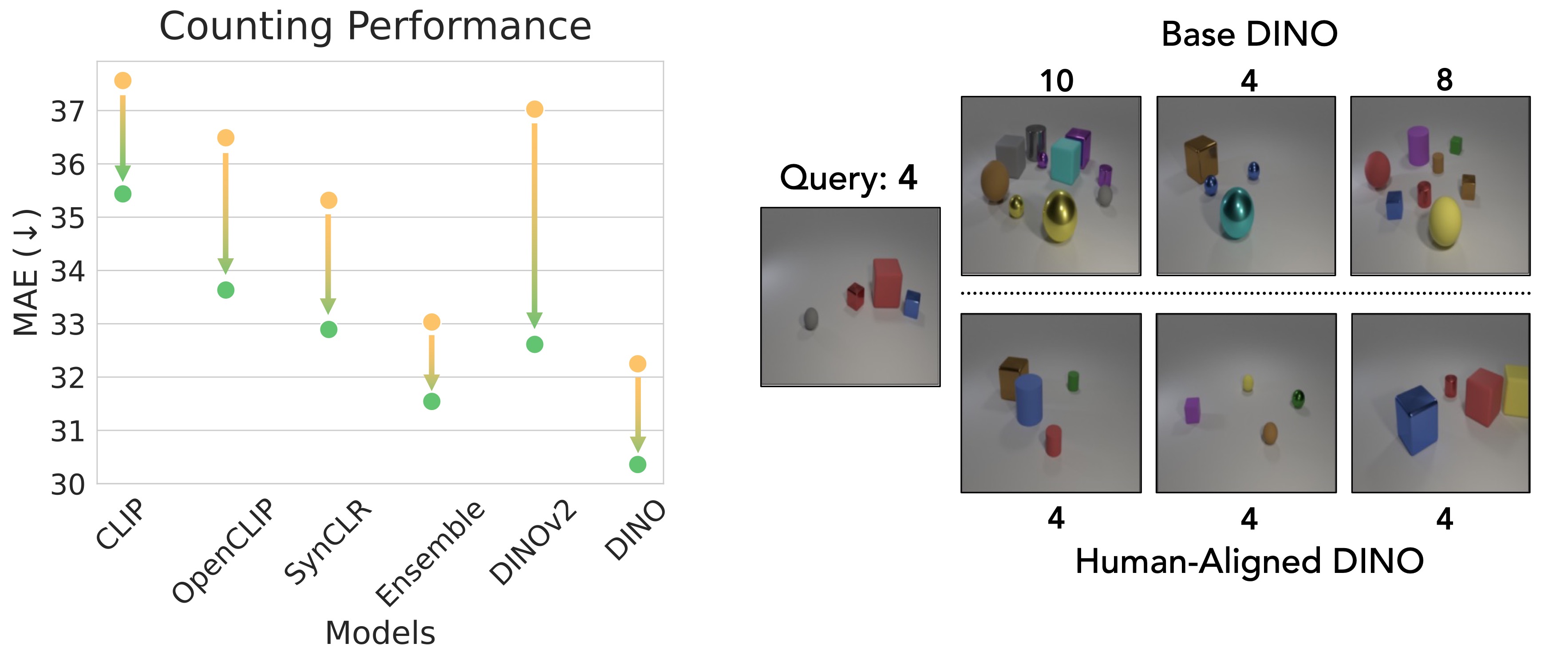
Another global understanding task we look at is counting. Across three different counting datasets, human-aligned models outperform pretrained models. This is somewhat surprising -- we wouldn't necessarily expect training on similarity judgements to impact awareness of object count in a scene.
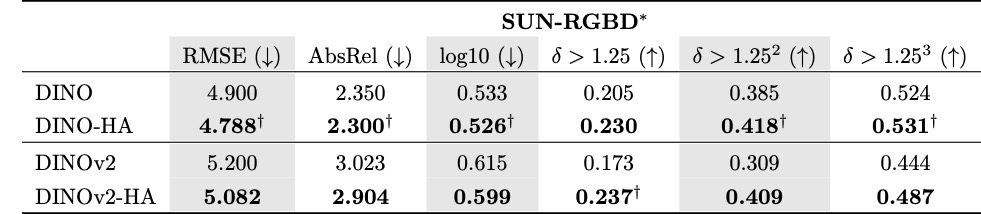
Finally, let's look at performance on dense prediction tasks: semantic segmentation and depth estimation. Once again, these tasks aren't intuitively related to the image similarity objective. Nevertheless, human-aligned DINO/DINOv2 outperform the pretrained models in most cases!

What are the limitations of perceptual alignment?
We've shown that human-aligned representations transfer better to a variety of global and dense prediction tasks. Are there any limitation cases?
In our paper, we show that performance does not improve for most standard image classification tasks, and in fact often decreases on natural-image datasets such as Flowers102 and Oxford-IIT Pets. One potential reason is that fine-tuning on NIGHTS degrades how well representations distinguish between fine-grained categories that are visually similar.
Implications
In this post we showed that models that are aligned to human perceptual judgements aren't just better at predicting image similarity, they actually capture knowledge useful to an array of different downstream tasks. Interestingly, training on NIGHTS (mid-level similarity) in particular leads to improvements, much more so than other perceptual datasets like BAPPS and THINGS.
We hope that this work opens up lots of interesting questions for future research. We investigate aligned representations through their competency at transfer tasks, but are there other ways of understanding what changes? Can we align models in a way that alleviates the limitations we found, but preserves the benefits?
For more details, results, and discussion, check out our paper!
Models and code
To try out our human-aligned models, otherwise known as the DreamSim models, head over to the DreamSim repo and/or
install our package with pip install dreamsim. You'll also find a pipeline for fine-tuning on the NIGHTS dataset.